 by Jordan Fields on Nov 4, 2021
by Jordan Fields on Nov 4, 2021
We get lots of questions from curious librarians about what EXACTLY is getting searched when someone searches Aspen, especially given how Aspen combines formats to create grouped works. Let’s dive in to see how searching works in our grouped work environment so we can better understand all of the benefits Aspen offers our patrons and staff.
Aspen first looks at the author, title, and format of each item as it is loaded and combines all editions and formats of that title into one search result, what we call a “grouped work,” during the process of record grouping. Read more on that here.
These records can come from many different sources, but the majority are typically MARC records from the ILS. Other sources of records might be API integrations, such as those we have with OverDrive, Hoopla, CloudLibrary, and Axis360, or MARC records loaded into Aspen from any source the library wants through a process called sideloading.
For searching, Aspen treats all of these records as if they are a single record, think of it like a grouped work record. Having a single record with all of this metadata is great when you consider searching for titles from sources that typically have less thorough data, such as those from some econtent vendors. Everything is more findable since you get all of the subjects, contributors, and everything else across records to help inform your search.
Much of this data is visible from any grouped work page. You can tell you’re on a grouped work page because you will see "GroupedWork" in the URL.
Here's an example from McKinney Public Libraries' Aspen catalog.
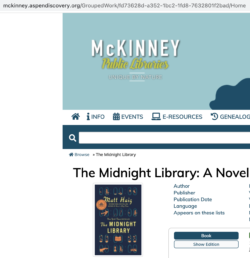
Note: If you don’t see "GroupedWork" in the URL, you are probably on the page for a specific bibliographic record. Just click on the “Go To Grouped Work” button under the Staff View to be sent to the Grouped Work page. See image on next page.

In the Staff View of a grouped work page, the first few sections (Grouping Information and Book Cover Information) have to do with the data. Aspen is displaying for the grouped work. To see the data Aspen is searching, look farther down and find the Solr Details section. Solr is the open source indexing platform that Aspen uses to index all of your materials. Here you’ll see much of the data from the individual bibliographic records that were grouped together.

The field labels in this section come from our Solr indexes rather than MARC, but most are pulling data from one or more MARC fields that correspond to the same kind of data in non-MARC bibliographic records.
The Solr field labels are more human-readable and typically easier to match to features like facets than MARC fields. As an example, let’s take a look at the subject_facet for the title The Midnight Library by Matt Haig from McKinney Public Libraries' catalog. McKinney Public Libraries owns this title in five different formats, 3 physical formats and 2 electronic formats.

The subject_facet field in the Solr Details section of the grouped work record is pulling data from the MARC 650 field across bibliographic records for all of those formats. Because of the variety of records the grouped work record is pulling from, the subject_facet field has some subjects that are specific to formats and also specific subjects that don’t appear in all of the individual MARC records.

For example, the subjects “Conduct of life,” “Regret,” and “Decision making” do not appear in the MARC record for the ebook. These are important themes to the book, and searching the grouped work record makes it possible to find the ebook by these key subjects.

Since we are talking about formats, you might be wondering how searching for a specific format works when we’re using the grouped work record to search across all of the records at the same time.
When you limit by a format in Aspen, you are only presented with titles that the library owns in that format. However, you are still searching all of the data from fields that describe the content of the item, Aspen is just hiding formats other than the one you selected. So, if I do a search for one of the subjects from the Midnight Library that does not not appear on the ebook record, and then limit my search to ebooks only, I can still find the Midnight Library as an ebook using the subject from the MARC record for the physical book.
As a special bonus for libraries that belong to a consortium, Aspen uses this data for all of the copies across your ILS, even if they are scoped out of your display for Aspen. So if one library is particularly excellent at adding local subject headings, all libraries benefit even if they don’t share materials.
This applies to lots of other data points in addition to subjects. If one the records for a title has audience data, all of the items in that grouped work have audience data - same for Lexile, same for series, and more!
Another benefit to having a grouped record is the ability to correct for some cagaloging mistakes. As 100% PERFECT as your library’s data might be (wink, wink), some library records do have mistakes.
When Aspen is combining four records into a grouped record and three of those records say the title is fiction and one says nonfiction, it will assume that the nonfiction categorization is incorrect because the majority of the records classify the title as fiction. How cool is that? By the way, it does the same for item records attached to the same bibliographic record with format to help correct for some of those pesky copy cataloging mistakes.
As much as patrons like seeing all of the formats of a title together in a single search result, there are even more benefits when you consider how Aspen uses grouped works to make searching better for everyone! We hope you enjoyed reading this blog and peeking behind the scenes at searching in Aspen!
Did You Know?
Did you know that you can use a blank search to find everything in Aspen? You can also use an *asterisk to perform a blank search. Then, add additional limiters to find results like 'new' or 'currently available' materials.
Read more by Jordan Fields